PRIVACY-PRESERVING AND
CONTENT-PROTECTING LOCATION BASED QUERIES
ABSTRACT:
In this paper we present a
solution to one of the location-based query problems. This problem is defined as
follows: (i) a user wants to query a database of location data, known as Points
Of Interest (POI), and does not want to reveal his/her location to the server
due to privacy concerns; (ii) the owner of the location data, that is, the
location server, does not want to simply distribute its data to all users. The location
server desires to have some control over its data, since the data is its asset.
Previous solutions have used a trusted anonymiser to address privacy, but
introduced the impracticality of trusting a third party. More recent solutions
have used homomorphic encryption to remove this weakness. Briefly, the user
submits his/her encrypted coordinates to the server and the server would
determine the user’s location homomorphically, and then the user would acquire
the corresponding record using Private Information Retrieval techniques. We
propose a major enhancement upon this result by introducing a similar two stage
approach, where the homomorphic comparison step is replaced with Oblivious
Transfer to achieve a more secure solution for both parties. The solution we
present is efficient and practical in many scenarios. We also include the
results of a working prototype to illustrate the efficiency of our protocol.
EXISTING SYSTEM:
The first solution to the problem was proposed
by Beresford, in which the privacy of the user is maintained by constantly
changing the user’s name or pseudonym within some mix-zone. It can be shown
that, due to the nature of the data being exchanged between the user and the
server, the frequent changing of the user’s name provides little protection for
the user’s privacy. A more recent investigation of the mix-zone approach has been
applied to road networks. They investigated the required number of users to
satisfy the unlinkability property when there are repeated queries over an interval.
This requires careful control of how many users are contained within the
mix-zone, which is difficult to achieve in practice. A complementary technique
to the mix-zone approach is based on k-anonymity. The concept of kanonymity was
introduced as a method for preserving privacy when releasing sensitive records.
This is achieved by generalisation and suppression algorithms to ensure that a record
could not be distinguished from (k − 1) other records. The solutions for LBS use a trusted anonymiser to
provide anonymity for the location data, such that the location data of a user
cannot be distinguished from (k − 1) other users.
DISADVANTAGES OF
EXISTING SYSTEM:
·
As solutions based on the use of a
central anonymiser are not practical.
· This incurs both processing and communication
overhead for the user device.
PROPOSED SYSTEM:
In this paper, we propose a novel protocol for
location based queries that has major performance improvements with respect to
the approach by Ghinita. Like such protocol, our protocol is organized
according to two stages. In the first stage, the user privately determines
his/her location within a public grid, using oblivious transfer. This data
contains both the ID and associated symmetric key for the block of data
in the private grid. In the second stage, the user executes a communicational
efficient PIR, to retrieve the appropriate block in the private grid. This
block is decrypted using the symmetric key obtained in the previous stage. Our
protocol thus provides protection for both the user and the server. The user is
protected because the server is unable to determine his/her location.
Similarly, the server’s data is protected since a malicious user can only decrypt
the block of data obtained by PIR with the encryption key acquired in the
previous stage. In other words, users cannot gain any more data than what they
have paid for. We also provide
results
from a working prototype showing the efficiency of our approach.
ADVANTAGES OF PROPOSED
SYSTEM:
·
This idea was extended to provide
database protection.
·
PIR is used to retrieve the data contained
within the appropriate cell.
·
It is more efficient.
SYSTEM
ARCHITECTURE:
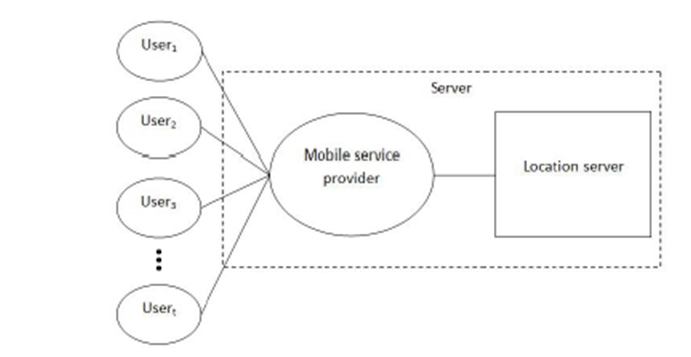
SYSTEM CONFIGURATION:-
HARDWARE REQUIREMENTS:-
ü Processor - Pentium –IV
ü Speed - 1.1 Ghz
ü RAM - 512 MB(min)
ü Hard
Disk - 40 GB
ü Key
Board - Standard Windows Keyboard
ü Mouse - Two or Three Button Mouse
ü Monitor - LCD/LED
SOFTWARE
REQUIREMENTS:
•
Operating system : Windows XP
•
Coding Language : Java
•
Data Base : MySQL
•
Tool : Net Beans IDE
REFERENCE:
Russell Paulet, Md. Golam Kaosar, Xun Yi, Elisa
Bertino, “Privacy-Preserving and
Content-Protecting Location Based Queries”
IEEE
TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, 2012 IEEE 28th International
Conference on Data Engineering.
No comments:
Post a Comment